更新一下吧,关于下载缺失的情况
特别注意,这不是对之前的爬虫的更新,而是另外一个全新的爬虫,请先使用第一个下载,再用这个补全
说明:
原楼层写太多了,新写一楼
想来想去还是补救一下,重新下载还是麻烦,况且每次下载完就要确认缺失情况,否则还得回头找链接,太麻烦
在漫画名后面添加id=和page=也是预留了补救措施
exe文件:
链接:
https://pan.baidu.com/s/1YzrOuHzp582dEW2JSxdJcw 提取码:q994 复制这段内容后打开百度网盘手机App,操作更方便哦
先放代码
复制代码- import os
- import shutil
- import requests
- import threading
- from faker import Faker
- faker = Faker(locale='zh_CN')
- glock = threading.Lock() #加锁
- def save_img_noreferer(path,src):
- headers = {
- 'User-Agent':faker.user_agent()
- }
- try:
- response = requests.get(src,headers=headers)
- except:
- save_img_noreferer(path,src)
- else:
- if response.status_code == 200: #状态码200,正常下载
- with open(path,'wb') as f:
- f.write(response.content)
- print(path+'下载完成')
- elif response.status_code == 522: #状态码522,超时重新下载,直至200下载成功
- save_img_noreferer(path,src)
- elif response.status_code == 404: #状态码404大概是格式后缀错误,改默认jpg为png
- src = src.replace('jpg','png')
- save_img_noreferer(path,src)
- else:
- print(src+',下载失败,网页状态码为:'+str(response.status_code))
- with open('常用的/error.txt','a',encoding='utf8') as f:
- f.write(src+',下载失败,网页状态码为:'+str(response.status_code)+'\n')
- def save_imgs(k,v): #多线程,配合save_img_noreferer()使用
- while True:
- glock.acquire()
- if len(k) ==0:
- glock.release()
- break
- else:
- path = k.pop()
- url = v.pop()
- glock.release()
- save_img_noreferer(path,url)
- def get_path_files(path):
- ls_path_files = []
- for i in os.walk(path):
- ls_path_files.append(i[0])
- del ls_path_files[0]
- return ls_path_files
- def get_dict_path_url(ls_path_files):
- path = []
- url = []
- for path_file in ls_path_files:
- page_should = int(path_file.split('page=')[-1]) #完整页码数
- page_actually = len(os.listdir(path_file)) #实际页码数
- if page_should == page_actually:
- pass
- else: #两者不相等说明缺失
- num = path_file.split('id=')[-1].split('page=')[0]
- ls_page_actually = []
- for i in os.listdir(path_file):
- ls_page_actually.append(int(i.split('.')[0]))
- for i in range(1,page_should+1):
- if i not in ls_page_actually: #对于缺失的,添加其本地路径和图片地址
- img_name = str(i)+'.jpg'
- path.append(os.path.join(path_file,img_name))
- url.append('https://i0.nyacdn.com/galleries/'+num+'/'+img_name)
- return dict(zip(path,url)) #返回本地路径:图片地址的字典
- def ctrl_x(path_old,path_new):
- try:
- shutil.move(path_old,path_new)
- except:
- with open('常用的/error.txt','w',encoding='utf8') as f:
- f.write('剪切时发生出错\t'+path_old)
- def main():
- path = input('请输入二级路径:')
- ls_path_files = get_path_files(path) #获取二级路径下各一级路径
- dict_path_url = get_dict_path_url(ls_path_files) #获取本地路径:图片地址的字典
- if len(dict_path_url) == 0:
- input('未发现有缺失,按任意键退出')
- elif len(dict_path_url) <= 10: #缺失小于等于10页,可能完全不能下载,用户选择
- a = input('缺失'+str(len(dict_path_url))+',可能不能下载了,是否继续处理(y)')
- if a == 'y': #多线程下载
- k = list(dict_path_url.keys())
- v = list(dict_path_url.values())
- for _ in range(64):
- consumer = threading.Thread(target=save_imgs,args=[k,v,])
- consumer.start()
- else: #缺失大于10页,以我检验4W+缺失的经历,应该不会超过10页,故自动补全
- k = list(dict_path_url.keys())
- v = list(dict_path_url.values())
- for _ in range(64):
- consumer = threading.Thread(target=save_imgs,args=[k,v,])
- consumer.start()
- if __name__ == '__main__':
- main()
|
用了os.walk(),老实说好用也不好用,反正我第一次用的时候过了很久才熟悉
其余看注释
使用说明:
①双击打开exe,等下如下图出现
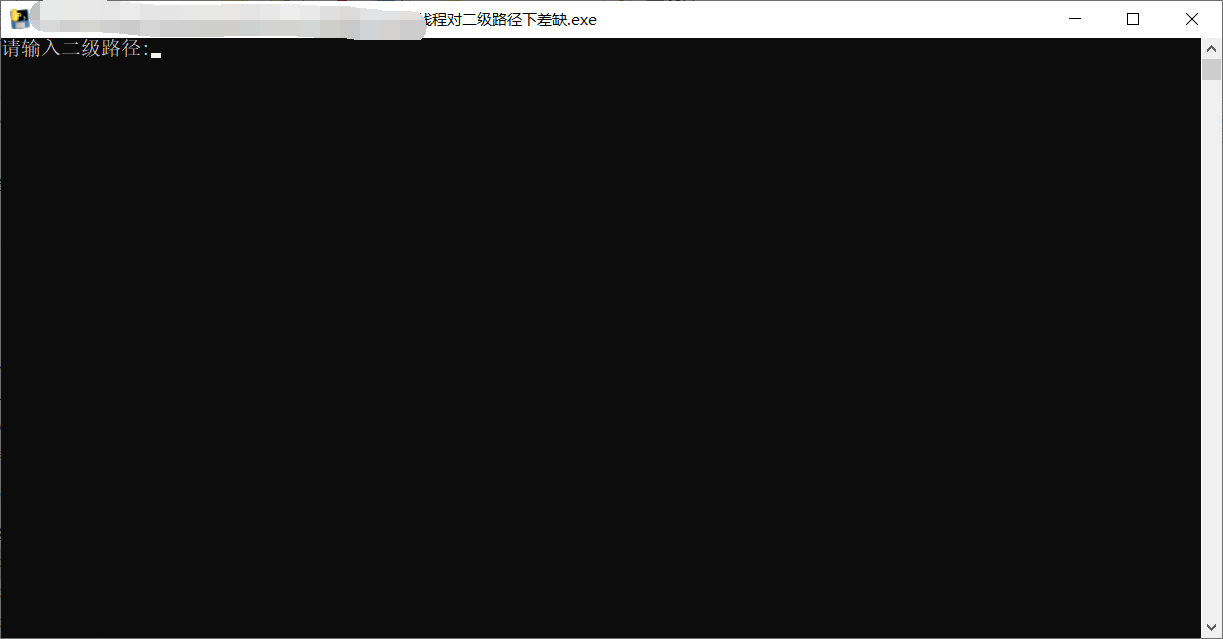
②按照提示复制粘贴二级路径,
(我对二级路径的定义是这样的:包含众多图片、文件夹名为漫画名的文件夹的路径叫一级路径。而包含大量一级路径文件夹的叫二级路径)(我不知道应该怎么叫,就这么解释,姑且贴个图,语文不好,见谅)(如果你下载了一本本漫画后没有做什么其他处理的话,那么这个二级路径应该是“D:\本子”)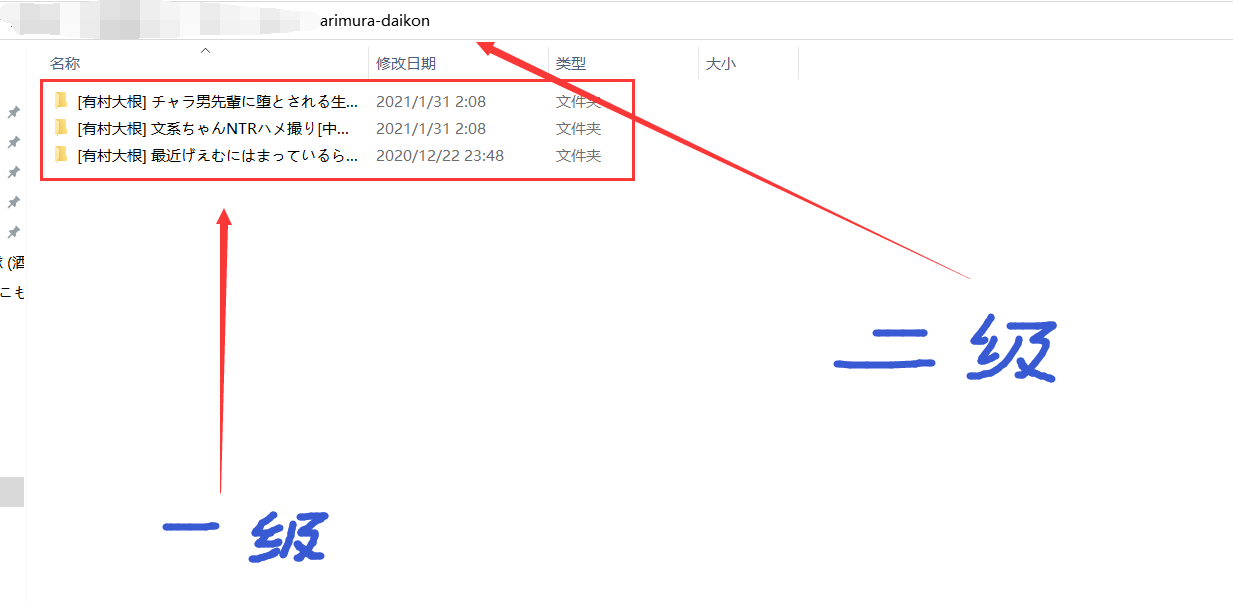
记得回车开始
③有三种情况处理:
1)不缺失,会提示“未发现有缺失,按任意键退出”
2)缺失小于等于10页,会询问你要不要继续,当且仅当输入
y继续,否则不做处理,处理完自动退出
3)如果大于10页,不做询问自动处理,处理完自动退出
注意:
①存在缺失完全不能下载的情况,我测试的时候是4W+不超过10页,所以阈值设的10
②程序自动退出是bug了还是,完成了,请再是一遍,理想情况下要么提示不缺失,要么提示缺失小于等于10
③如有问题请仔细阅读使用说明,仍不能解决请私信问题
④对于二级路径再次说明:二级路径是包含众多漫画的文件夹,漫画的文件夹下只能包含图片。否则可能会出现未知错误,对此问题不更新 






